RDMA(远程直接数据存取),以其对业务带来的高性能、低延时优势,在数据中心尤其是AI、HPC、大数据等场景得到了广泛应用。为保障RDMA的稳定运行,基础网络需要提供端到端无损零丢包及超低延时的能力,这也催生了PFC、ECN等网络流控技术在RDMA网络中的部署。在RDMA网络中,如何合理设置MMU(缓存管理单元)水线是保证RDMA网络无损和低延时的关键。本文将以RDMA网络作为切入点,结合实际部署经验,分析MMU水线设置的一些思路。
什么是RDMA?
RDMA(Remote Direct Memory Access),通俗的说就是远程的DMA技术,是为了解决网络传输中服务器端数据处理的延迟而产生的。

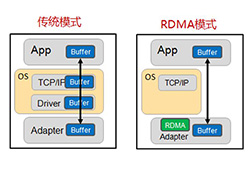
传统模式与RDMA模式工作机制对比
如上图,在传统模式下,两台服务器上的应用之间传输数据,过程是这样的:
- 首先要把数据从应用缓存拷贝到Kernel中的TCP协议栈缓存;
- 然后再拷贝到驱动层;
- 最后拷贝到网卡缓存。
多次内存拷贝需要CPU多次介入,导致处理延时大,达到数十微秒。同时整个过程中CPU过多参与,大量消耗CPU性能,影响正常的数据计算。
在RDMA 模式下,应用数据可以绕过Kernel协议栈直接向网卡写数据,带来的显著好处有:
- 处理延时由数十微秒降低到1微秒内;
- 整个过程几乎不需要CPU参与,节省性能;
- 传输带宽更高。
RDMA对于网络的诉求
RDMA在高性能计算、大数据分析、IO高并发等场景中应用越来越广泛。诸如iSICI, SAN, Ceph, MPI, Hadoop, Spark, Tensorflow等应用软件都开始部署RDMA技术。而对于支撑端到端传输的基础网络而言,低延时(微秒级)、无损(lossless)则是最重要的指标。
低延时
网络转发延时主要产生在设备节点(这里忽略了光电传输延时和数据串行延时),设备转发延时包括以下三部分:
存储转发延时:芯片转发流水线处理延迟,每个hop会产生1微秒左右的芯片处理延时(业界也有尝试使用cut-through模式,单跳延迟可以降低到0.3微秒左右);
Buffer缓存延时:当网络拥塞时,报文会被缓存起来等待转发。这时Buffer越大,缓存报文的时间就越长,产生的时延也会更高。对于RDMA网络,Buffer并不是越大越好,需要合理选择;
重传延时:在RDMA网络里会有其他技术保证不丢包,这部分不做分析。
无损
RDMA在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。在传统网络模式下,要想实现不丢包最主要的手段就是依赖大缓存,但如前文所说,这又与低延时矛盾了。因此,在RDMA网络环境中,需要实现的是较小Buffer下的不丢包。
在这个限制条件下,RDMA实现无损主要是依赖基于PFC和ECN的网络流控技术。
PFC
PFC(Priority-based Flow Control),基于优先级的流量控制。是一种基于队列的反压机制,通过发送Pause帧通知上游设备暂停发包来防止缓存溢出丢包。

PFC工作机制示意图