包括图灵在内的大部分研究者都认为人能够按照自己的经验做出正确的决定,而智能机器也应该和人类一样来完成这些决定,因此我们的工作就简化成为在智能测试中去判断智能机器是否完成了和人类一样的决定。
但是在某些情况下,哪怕是人类也很难确定什么是正确的,例如著名的铁轨问题:你是一辆刹车失灵的火车司机,在你前面的铁轨上有5个人被绑在轨道上,你可以选择切换到另外轨道,另外那条轨道上只有1个人绑在铁轨上,那么请问你会选择撞死5个人还是切换轨道撞死1个人?对于这个问题本文中不做更多的讨论,即使是人类,在这个问题上都很难做出“正确的”决定,更何况智能机器?所以在本文中我们不去讨论这些问题,我们也不会为伦理问题设置智能性测试。
4.2. 测试结果的自动实时分析
图灵测试和现在很多新的智能测试的区别在于,图灵测试用人来做判定,而新的智能测试使用的是机器来做判定。之所以这么做的原因在于我们清晰的定义了任务,同时很多情况下没有机器的帮助人很难完成正确的判定。
以智能车测试为例,为了节约成本,我们往往在某一条测试路线上设置了多个测试任务,车辆需要不停歇的完成多个测试任务。
例如在中国智能车未来挑战赛中就设置了14个测试任务,分别是U-Turn,通过T字型路口,通过十字路口,避让作业车,隧道,停止标志,避让行人,右转,乡村道路,避让自行车,施工区域,限速,停车。车辆需要连续通过这些任务点,为了能够自动测评,我们需要使用V2X设备连接车辆上的传感器和数据中心,上传车辆数据到数据中心来完成自动测评。
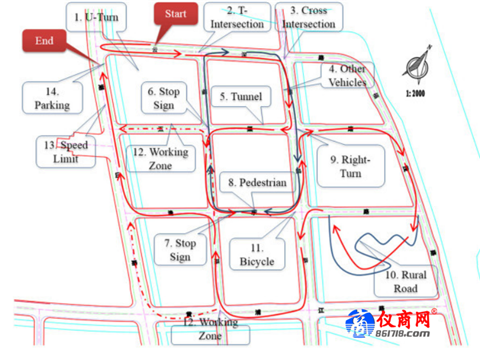
图9. 智能车比赛测试项
青岛慧拓智能机器有限公司联合清华大学一起开发了自动测评系统并成功应用于此次比赛中。如图10所示,左边展示的是正在比赛中的5辆车的实时轨迹和实时排名,右边屏幕里是实时的视频回传数据,展示着裁判车数据,比赛车辆数据,以及场边摄像头数据。这些数据通过V2X或者4G的方式传回数据中心。
在2009年-2015年的比赛中,比赛由裁判来人工打分,这种方式比较主观,也非常耗时。在2017年比赛中,大部分的任务可以通过回传过来的数据实现自动打分。我们同样能够通过深度学习的方式用视觉的方式来检查车辆是否有压线,来实现自动打分,如图11所示。

图10. 智能车比赛实时评测

图11. 实时压线检测
4.3. 驾驶员在环测试
按照上文中说到,我们最终的目的是让机器代替人来评价智能性测试结果。但是目前阶段,这种情况却难以完全实现。
首先,测试任务的描述需要由人类专家来完成。所有的任务描述都是使用人类语言,目前也并没有一种计算机语言能够更好的完成该任务。机器的智能水平往往受限于它的设计者,所以我们最终总是还是需要用人类的智慧来在衡量测试结果的基础上提升机器的智能性水平。
其次,人类专家能够按照自己的经验更好的帮助机器设计那些极限的测试任务。
最后,人类是智能性测试的最后决策者,往往由机器做出的判断还要由人类来检查。就像在2017年中国智能车未来挑战赛中视频回传系统就是方便人类专家随时能够监督智能车的表现,这能够让人类和自动打分系统同时以对方的判断为基础改善自己的评判能力。
4.4. 用测试来进行智能水平分级
SAE把汽车自动化水平分为从无自动化到完全自动化六个级别,但是在该分级体系中并没有给出明确的需要完成的任务。现在有更多人认为,只有明确了分级系统中的测试任务,才能更好的对汽车智能性水平进行分级。