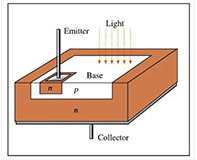
引言
看过《三体》的朋友们,一定对震撼的人列计算机有所印象:冯 · 诺依曼让秦始皇安排三千万个士兵组成的人列计算器,通过士兵举黑白旗显现的信号代替了二进制进行运算;通过骑马的轻转兵在整个系统间传递信息代替了总线进行数据传输;并利用三百万名文化程度较高的学者每个人手中的记录本和笔,负责记录运算结果代替了存储器。这就形成了控制器和运算单元、总线以及存储器的概念。
不知道读者在阅读这一段的时候是否有一个疑问,为什么不能有一个聪明的士兵既能做运算又能记录运算结果,实现“存算一体化”, 从而降低包括数据搬移在内所带来的巨大开销?
应用背景
正像三体中描述的人列计算机,目前大多数芯片系统采用的是冯·诺依曼架构,处理器和存储器由总线连接,数据需在二者之间来回搬运。但随着大数据和人工智能时代的到来,传统的计算存储分离的硬件架构不得不面对冯·诺伊曼瓶颈。数据搬移带来的能耗开销使得存算分离的传统架构难以满足低功耗的系统设计需求。在一些神经网络硬件加速器中,核心的数据处理消耗的能量只有不到10%,除此之外与数据传输相关的能耗才是制约整个系统能效的关键问题。
如图1所示,为了打破冯·诺依曼瓶颈的束缚,存算一体的计算架构开始兴起,逐渐从近存储的计算范式到以存储为中心的计算范式演进。近年来,半导体制造工艺的发展和人工智能领域的崛起,为存算一体技术提供了全新的制造平台和产业驱动力。除了在人工智能及深度学习领域的广泛应用,存算一体架构同样适用于未来主流的感存算一体芯片和类脑芯片。

图1 冯·诺依曼架构和存算一体架构示意图
存算一体芯片旨在把传统以计算为中心的架构转变为以数据为中心的架构,直接利用存储器进行数据处理。近年来非易失性存储器技术的发展,为存算一体芯片的高效实施带来了新的曙光。
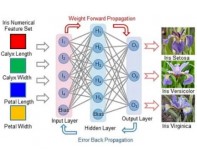
我国在这方面的研究也取得了一系列的创新成果,例如2016年北京大学康晋峰教授团队提出以阻变器件替代传统的CMOS器件来实现逻辑计算。构建了基于触发电平时序的逻辑计算类型,得到可以实时逻辑重构的计算、存储一体化并行处理硬件架构。2021年,中国科学院微电子研究所的刘明团队设计了超薄铁电隧道结进行时间数据学习的节能而稳健的储层计算系统,该系统以高的能效、处理速度 和识别精度完成数字序列分类。2021年复旦大学周鹏团队研究出二维铁电沟道晶体管(2D FeCTs),该FeCTs兼具优异的非易失存储功能和神经拟态能力。如图2所示,该器件成功实现了对鸢尾花图像的高精度分类。2022年国防科技大学电子科学学院徐晖教授课题组与复旦大学芯片与系统前沿技术研究院刘琦教授课题组合作,首次实现了一种与CMOS工艺完全兼容的氧化铪基反铁电神经元。该反铁电晶体管能模拟生物神经元积分发射特性,且由于其自发的去极化现象避免了大尺寸电容和复位电路的使用,有效提高了神经形态计算芯片集成度。如图3所示构建的784×400×10双层神经网络,手写体识别率高达96.8%,对促进新原理器件在图像、语音等智能化处理场景的应用具有重要意义。2022年,华东师范大学段纯刚教授团队利用铁电突触晶体管神经网络成功实现了联想学习,达到输入了不完整的像素,也可以从硬件成功输出完整像素的图像识别功能。

图3 双层全铁电SNN示意图及基于FeFET突触和AFeFET神经元网络的硬件
测试方案介绍
存算一体芯片旨在把传统以计算为中心的架构转变为以数据为中心的架构,直接利用存储器进行数据处理。存算一体芯片在当代研究的最新神经元网络中扮演高速存储计算单元,其主要技术路线有通过阻变,容变等方式实现。存算一体芯片在当代研究的最新神经元网络中扮演高速存储计算单元。在研发阶段,目前很多机理的存算一体芯片都需要反复测试验证迭代,必须需要有一套合适的测试系统加速这一过程。在这个过程中,如何快速将单个单元的测量扩展到阵列形式的测量,是实验室必须要解决的一个测量难题。
测试需求
◾ 单个单元的性能测试
◾ 可扩展的多单元性能测试
◾ 存算一体阵列芯片的测试
◾ 模拟应用的测试方法
阵列测试流程
1. 对阵列中的行列每个单元通过施加脉冲,进行预设置,记录I-V特性。
2. 预设置整体阵列后,再次对每个行列单元按序列施加脉冲,记录充放电情况及极化反转等特性。
3. 不同的序列脉冲施加,测试不同行列激励下的不同反应。
4. 测试过程中需要反复施加脉冲,并且同步测量I-V特性并需要友好方便的编程方式满足不同的激励测试需求